If you use this service, could you please send us a mail to npsang@ibcp.fr with details about your usage of the NPSA service (tools used, frequency, type of sequence, ..) ?
Could you explain what makes this service unique for you ?
Could you please add information about your country and your laboratory ?
Thanks
Work with a database
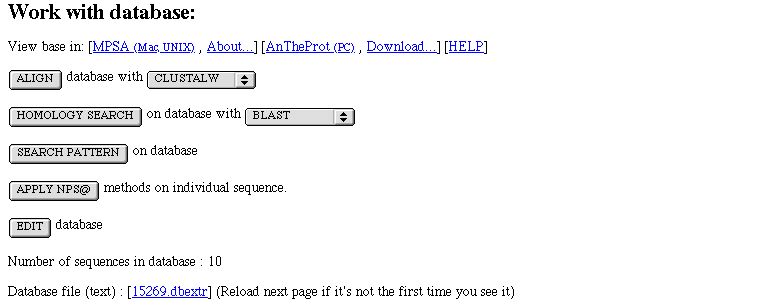
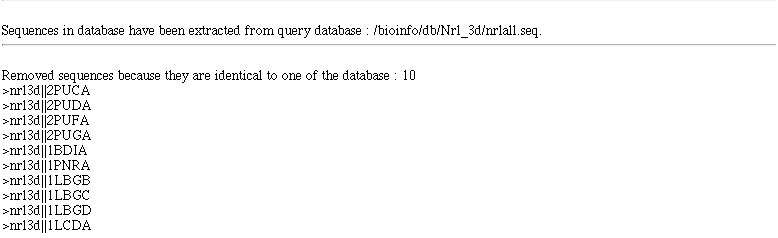
In NPS@ you can work with a database.
The database can have four origins :

 In NPS@ you can work with a database.
In NPS@ you can work with a database.