If you use this service, could you please send us a mail to npsang@ibcp.fr with details about your usage of the NPSA service (tools used, frequency, type of sequence, ..) ?
Could you explain what makes this service unique for you ?
Could you please add information about your country and your laboratory ?
Thanks
MULTALIN help
A brief introduction to MULTALIN
MULTALIN is a progressive multiple sequence alignment program which allows you to align several biological sequences using hierarchical
clustering.
For further details, see MULTALIN documentation.
When you work with a database in NPS@
(if the database contains at least two sequences).
The database to align cannot have more than 250,000 characters.
So, for example, you can use MULTALIN to align a database of similar sequences built from a
BLAST search or a
PATTINPROT search.
Parameters
With the output order parameter you can choose to show the aligned sequences in the input order or in the aligned order.
The symbol comparison table sets the matrix to use scoring matches in the alignment.
The gap penalty value and the gap length value set the penalties for gaps. The alignment score is then the sum of
matches minus gap penalty value times the number of gaps and minus the gap length value times the total length of gaps.
If the extremity gap penalty option is selected, end gaps are penalized as internal gaps.
With one iteration only the alignment is done more quickly but it may not be the most accurate.
The unweighted sequences option gives the same weight (1.0) to all sequences.
The scoring method option sets how the pairwise scores are computed.
Then you set two conservation levels. For each position, MULTALIN computes the most present residue. If the residue is present
with a percentage equal or greater than the first conservation level, it will be write in upper-case letter in the consensus line. If
it's present with a percentage equal or greater than the second consensus level but lesser than the first one, it will be printed in
lower-case letter.
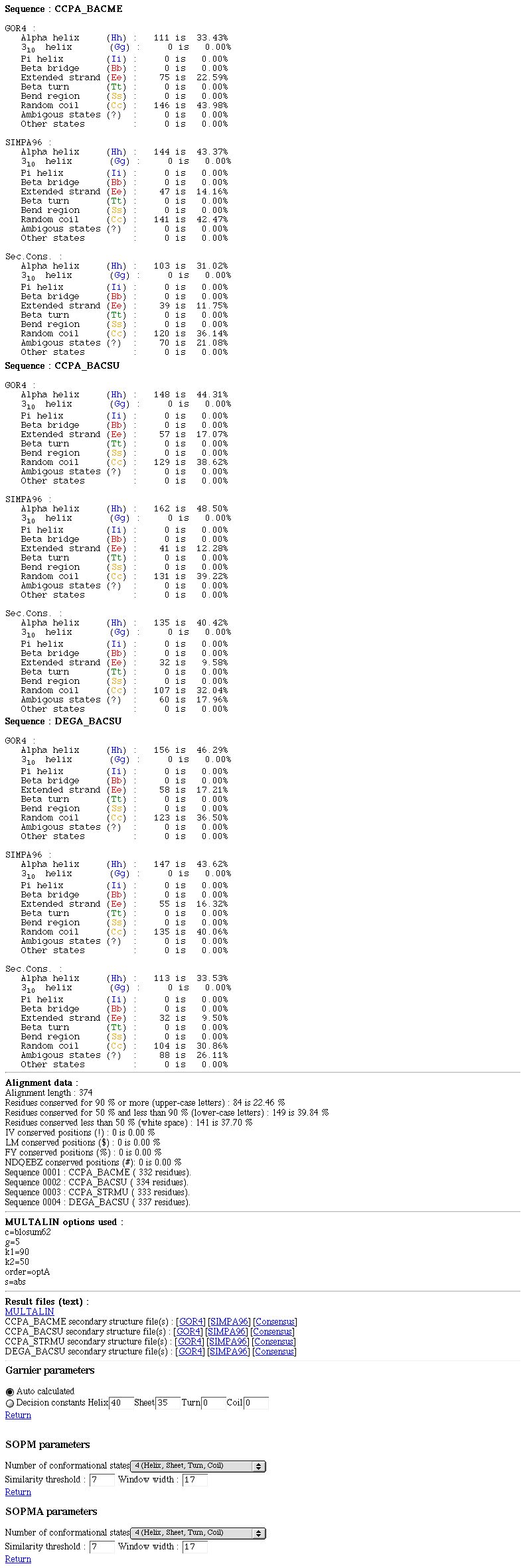
NPS@ MULTALIN output example
The NPS@ MULTALIN output is divided into three parts.
PART 1:
In this part, you have a form to work with the alignment. Your choices are validate when you click on the SHOW button. You can :
show residues with different options (all or using conservation level options). The most interesting option is the
"using conservation level" one. With it you, display only resiues that have a conservation level equal or above the value
you type in.
select secondary structure prediction methods to compute and display. This in the case of proteins and when you have no
more than 50 sequences. A method with the "(Do it alone)" sentence has to be computed alone (it must be
the only one newly selected before the next click on "SHOW" button). Otherwise, you won't have your response because of the
timeout (these methods can take 5 minutes or more by sequence). You can also show all methods with or without
secondary consensus only the consensus. You can also
see the percentage of each secondary structure element (HETC...) for each method.
PART 2:
It's the color coded alignment with or without secondary structure predcitions inserted.
You can see :
MPSA/ANTHEPROT link to
view data in these local protein sequence analysis softwares.
You can then download the alignment in MPSA/ANTHEPROT (currently the secondary structure are not downloaded contrary to CLUSTALW).
The alignment width must be equal to 60 for download in these softwares.
The alignment with inserted secondary structure predcitions if any.
PART 3:
You have :
The percentage of each secondary structure element (if wanted) for each prediction and for each sequence.
Some data on the alignment (length, number of identities,...).
MULTALIN options used.
Links on result text files (MULTALIN, secondary structure prediction method outputs,...).

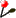 A brief introduction to MULTALIN
A brief introduction to MULTALIN