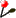 When you see in NPS@ the sentence "Pattern value", you must paste a pattern with
PROSITE syntax as indicated below.
When you see in NPS@ the sentence "Pattern value", you must paste a pattern with
PROSITE syntax as indicated below.
When you see in NPS@ the sentence "Pattern value", you must paste a pattern with
PROSITE syntax as indicated below.
What is the PROSITE syntax ?
You can see below a PROSITE entry.
ID LY6_UPAR; PATTERN.
AC PS00983;
DT JUN-1994 (CREATED); JUN-1994 (DATA UPDATE); JUL-1998 (INF UPDATE).
DE Ly-6 / u-PAR domain signature.
PA [EQR]-C-[LIVMFYAH]-x-C-x(5,8)-C-x(3,8)-[EDNQSTV]-C-{C}-x(5)-C-
PA x(12,24)-C.
NR /RELEASE=36,74019;
NR /TOTAL=28(20); /POSITIVE=28(20); /UNKNOWN=0(0); /FALSE_POS=0(0);
NR /FALSE_NEG=2; /PARTIAL=0;
CC /TAXO-RANGE=??E?V; /MAX-REPEAT=3;
CC /SITE=2,disulfide; /SITE=5,disulfide; /SITE=7,disulfide;
CC /SITE=10,disulfide; /SITE=13,disulfide; /SITE=15,disulfide;
DR P51447, CD59_AOTTR, T; P46657, CD59_CALSQ, T; Q28216, CD59_CERAE, T;
DR Q00996, CD59_HSVSA, T; P13987, CD59_HUMAN, T; Q28785, CD59_PAPSP, T;
DR P27274, CD59_RAT , T; Q14210, E48A_HUMAN, T; Q99445, GML_HUMAN , T;
DR P05533, LY6A_MOUSE, T; P09568, LY6C_MOUSE, T; P35460, LY6F_MOUSE, T;
DR P35461, LY6G_MOUSE, T; P35459, THYB_MOUSE, T; P35457, UPAS_MOUSE, T;
DR P49616, UPAR_RAT , T; P51573, UPAS_RAT , T; Q05588, UPAR_BOVIN, T;
DR Q03405, UPAR_HUMAN, T; P35456, UPAR_MOUSE, T;
DR P47777, CD59_SAISC, N; Q64253, LY6E_MOUSE, N;
3D 1CDQ; 1CDR; 1CDS; 1ERG; 1ERH;
DO PDOC00756;
The pattern is in lines starting with PA and its value is in this example :
So, our pattern example could be "translated" in :
[EQR]-C-[LIVMFYAH]-x-C-x(5,8)-C-x(3,8)-[EDNQSTV]-C-{C}-x(5)-C-x(12,24)-C.
1st element [EQR] : I want E, Q or R
2nd element C : I want only C
3rd element [LIVMFYAH] : I want L, I, V, M, F, Y, A, or H
4th element x : I want any residue
5th element C : I want only C
6th element x(5,8) : I want any residue for 5 to 8 times
7th element C : I want only C
8th element x(3,8) : I want any residue for 3 to 8 times
9th element [EDNQSTV] : I want E, D, N, Q, S, T, or V
10th element C : I want only C
11th element {C} : I want all residue but C (I don't want C)
12th element x(5) : I want any residue 5 times
13th element C : I want only C
14th element x(12,24) : I want any residue for 12 to 24 times
15th element C : I want only C
Some patterns matching the syntax :
CD59_AOTTR:
Q-C-Y-S-C-PYPTTQ-C-TMTT-N-C-T-SNLDS-C-LIAKAGSRVYYR-C
Q-C-Y-S-C-PYPTTQ-C-TMTT-N-C-T-SNLDS-C-LIAKAGSRVYYRCWKFED-C
GML_HUMAN :
R-C-H-D-C-AVINDFN-C-PNIR-V-C-P-YHIRR-C-MTISIRINSRELLVYKN-C
R-C-H-D-C-AVINDFN-C-PNIR-V-C-P-YHIRR-C-MTISIRINSRELLVYKNCTNN-C